
Trong bối cảnh hệ thống ngày càng phức tạp, IT Operations không chỉ cần phản ứng nhanh với sự cố mà còn phải đảm bảo toàn bộ quy trình vận hành diễn ra trơn tru, có kiểm soát và có khả năng cải tiến liên tục.
Tại BiPlus, cách tiếp cận Modern IT Operations được triển khai dựa trên hệ sinh thái Atlassian, với trung tâm là Jira Service Management (JSM) kết hợp cùng Rovo AI. Thay vì vận hành trên nhiều công cụ rời rạc, giải pháp này tập trung vào việc kết nối dữ liệu, quy trình và con người trong một hệ thống thống nhất.
Trong bài viết này, BiPlus chia sẻ một use case thực tế từ chính đội DevOps nội bộ, theo đúng quy trình xử lý sự cố đang được áp dụng mỗi ngày.
Tập trung dữ liệu và tạo incident có ngữ cảnh
Từ alert rời rạc đến một điểm tiếp nhận thống nhất
Trong môi trường vận hành thực tế, alert thường đến từ nhiều hệ thống monitoring khác nhau như Prometheus, Datadog hay CloudWatch. Mỗi công cụ cung cấp một lát cắt của hệ thống, nhưng khi đứng riêng lẻ, chúng không đủ để đưa ra quyết định nhanh.
Tại BiPlus, toàn bộ alert được tập trung về Jira Service Management, tạo thành một điểm tiếp nhận duy nhất. Tại đây, các cảnh báo liên quan được tự động gom nhóm, phân loại và sắp xếp theo mức độ ưu tiên. Điều này giúp đội DevOps không còn phải theo dõi nhiều màn hình khác nhau, mà có thể nắm được toàn bộ tình trạng hệ thống ngay tại một nơi.
Từ alert đến incident – xử lý nhanh với đầy đủ ngữ cảnh
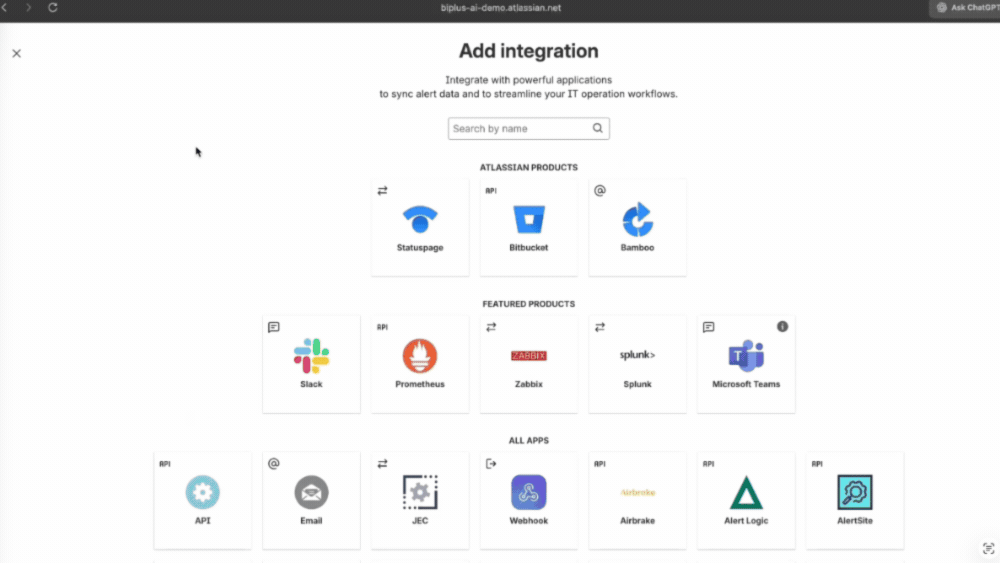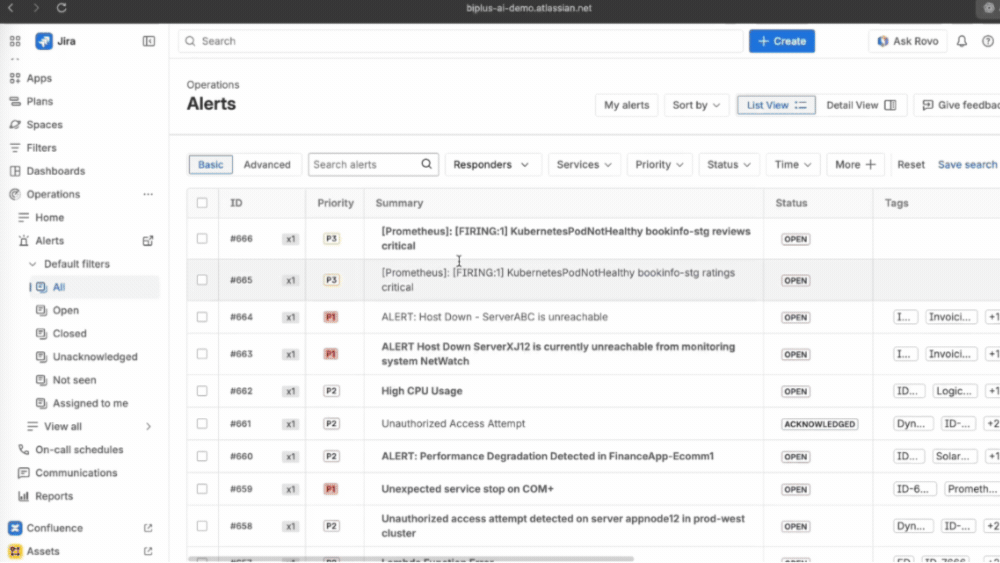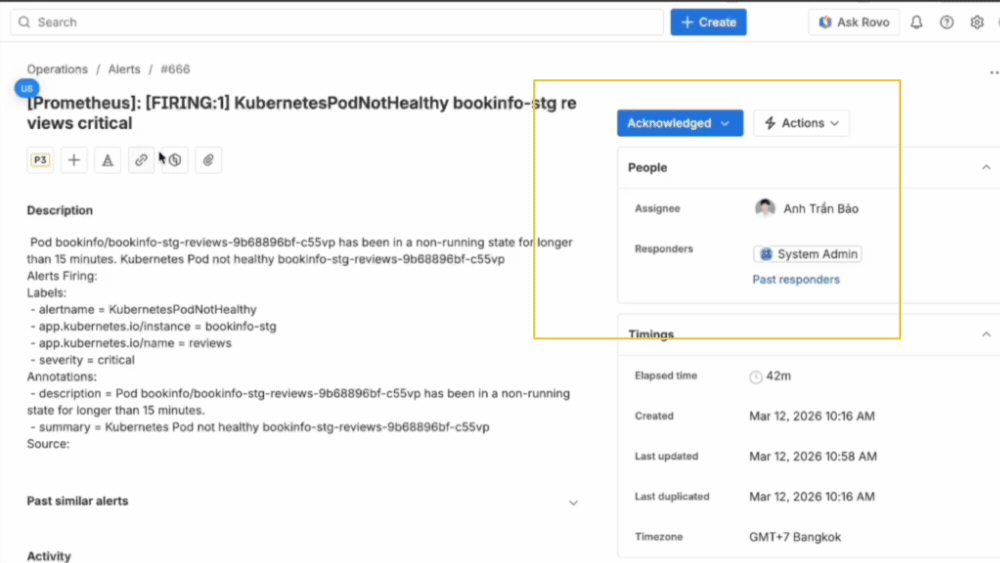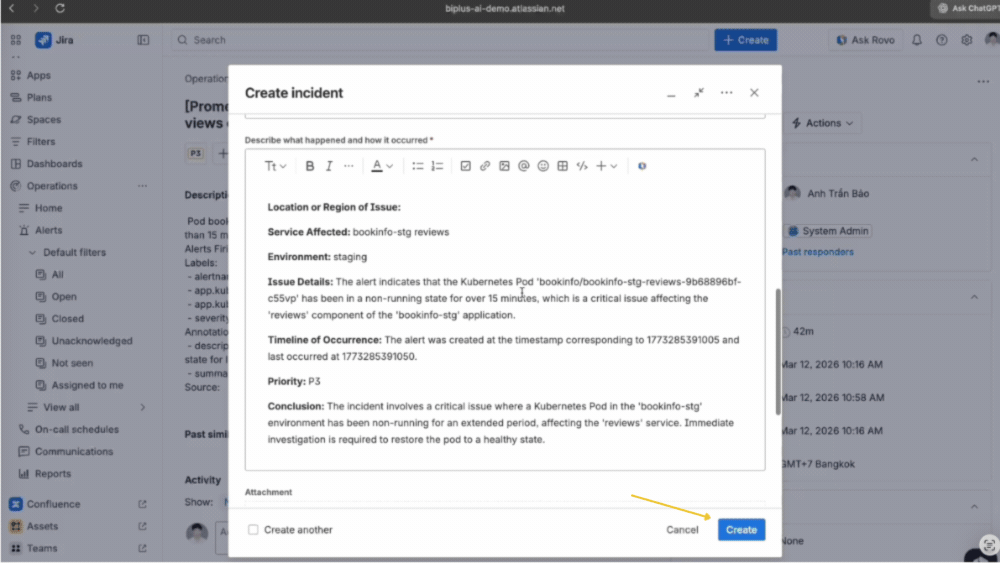
Khi một alert được xác nhận là sự cố thực sự, việc chuyển đổi sang incident diễn ra ngay lập tức mà không cần nhập lại dữ liệu. Toàn bộ thông tin kỹ thuật được giữ nguyên, giúp loại bỏ bước tổng hợp thủ công vốn rất tốn thời gian.
Ngay khi incident được tạo, Rovo AI tự động đề xuất phần tóm tắt và mô tả dựa trên dữ liệu alert và bối cảnh hệ thống. Người trực ca chỉ cần rà soát nhanh và có thể bắt đầu xử lý ngay. Nhờ đó, thời gian phản hồi ban đầu được rút ngắn đáng kể, đặc biệt trong các tình huống cần xử lý khẩn cấp.
Điều phối xử lý sự cố với AI và hệ thống tri thức
Hiểu đúng impact và điều phối ngay từ đầu
Một trong những thách thức lớn của IT Ops là không nắm rõ mức độ ảnh hưởng của sự cố ngay từ đầu. Điều này thường dẫn đến việc xử lý thiếu trọng tâm hoặc mất thời gian điều phối.
Với JSM, mỗi incident được liên kết trực tiếp với CMDB, giúp hiển thị rõ dịch vụ bị ảnh hưởng, các thành phần liên quan và người chịu trách nhiệm. Nhờ đó, đội ngũ có thể nhanh chóng xác định mức độ ưu tiên, biết cần liên hệ với ai và tập trung xử lý vào đúng điểm gây ảnh hưởng lớn nhất. Đồng thời, các stakeholder liên quan cũng được tự động thông báo, giúp việc phối hợp diễn ra ngay từ đầu mà không cần chờ đợi.
AI hỗ trợ xử lý và tận dụng tri thức sẵn có
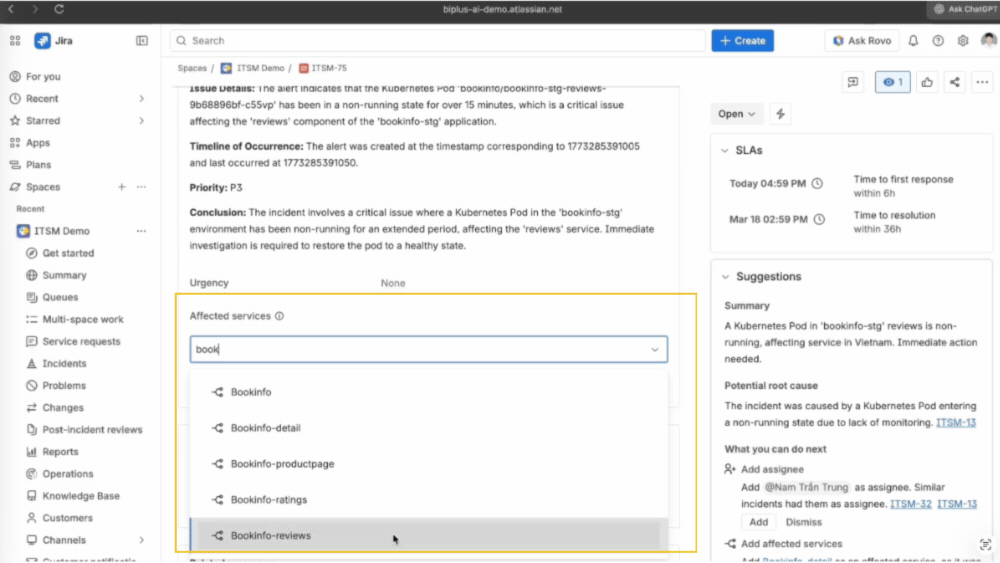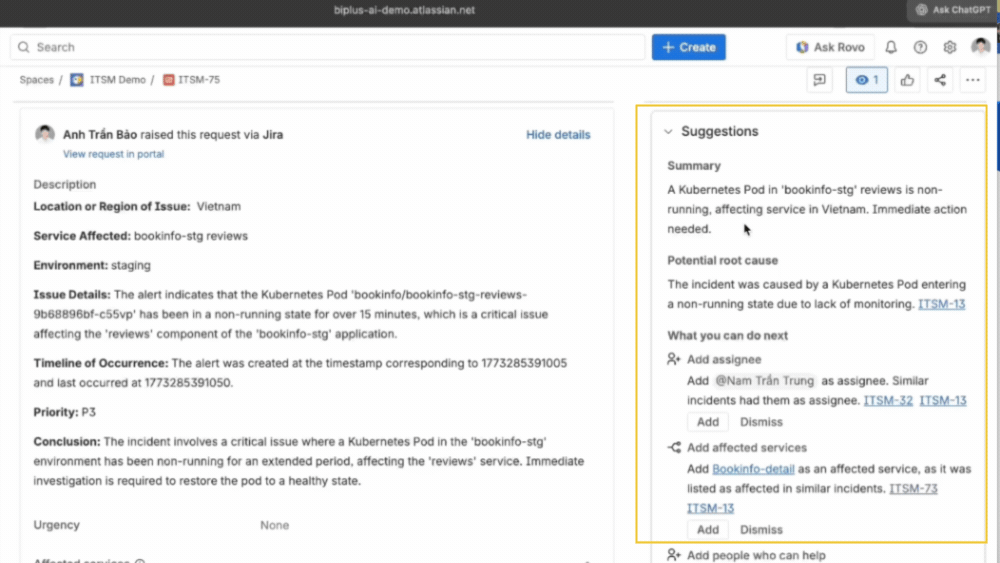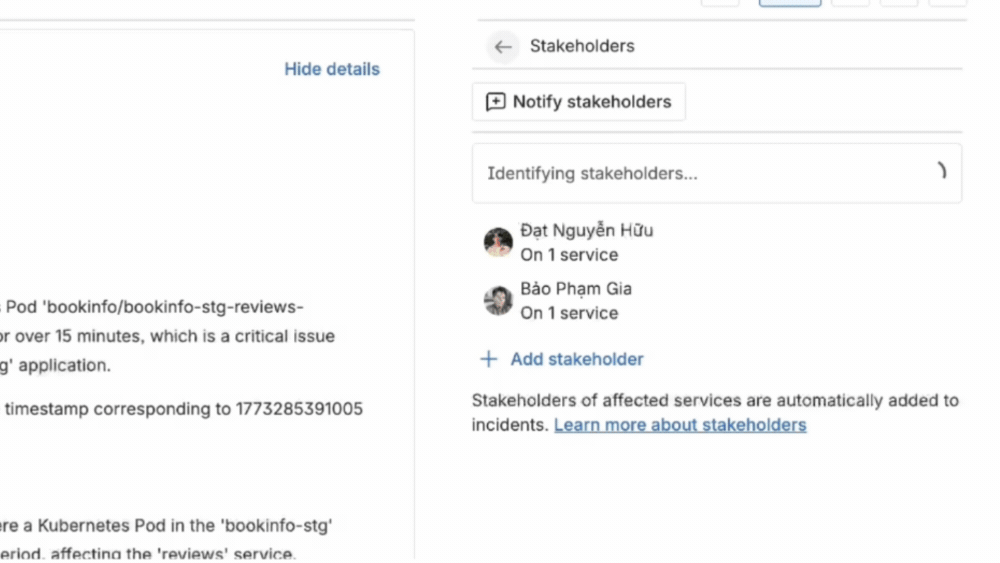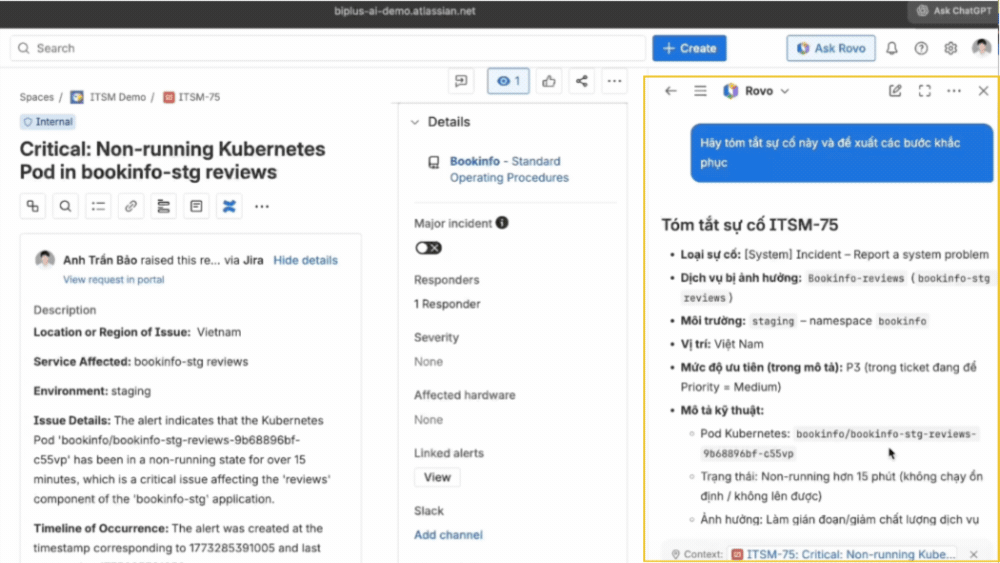
Trong suốt quá trình xử lý incident, Rovo AI đóng vai trò như một trợ lý đồng hành. Người xử lý có thể yêu cầu AI tóm tắt tình trạng hiện tại, xem lại các bước đã thực hiện và nhận gợi ý cho các hành động tiếp theo.
Không chỉ dừng lại ở đó, hệ thống còn cho phép truy cập nhanh vào kho tri thức đã được xây dựng trước đó, bao gồm tài liệu vận hành, hướng dẫn xử lý và các incident tương tự trong quá khứ. Nhờ vậy, đội ngũ không cần bắt đầu lại từ đầu mỗi lần có sự cố, mà có thể dựa trên kinh nghiệm đã được tích lũy để xử lý nhanh và nhất quán hơn.
Chuẩn hóa xử lý bằng playbook
Đối với những sự cố lặp lại, BiPlus chuẩn hóa thành các playbook và gắn trực tiếp vào hệ thống. Mỗi playbook mô tả rõ ràng các bước cần thực hiện, từ kiểm tra log, xác nhận chỉ số cho đến các hành động khắc phục.
Việc chuẩn hóa này giúp giảm phụ thuộc vào kinh nghiệm cá nhân, đồng thời đảm bảo mọi thành viên trong đội đều có thể xử lý theo cùng một cách tiếp cận. Điều này đặc biệt hữu ích trong các ca trực hoặc khi có thành viên mới tham gia vào quá trình vận hành.
Từ xử lý sự cố đến cải tiến liên tục
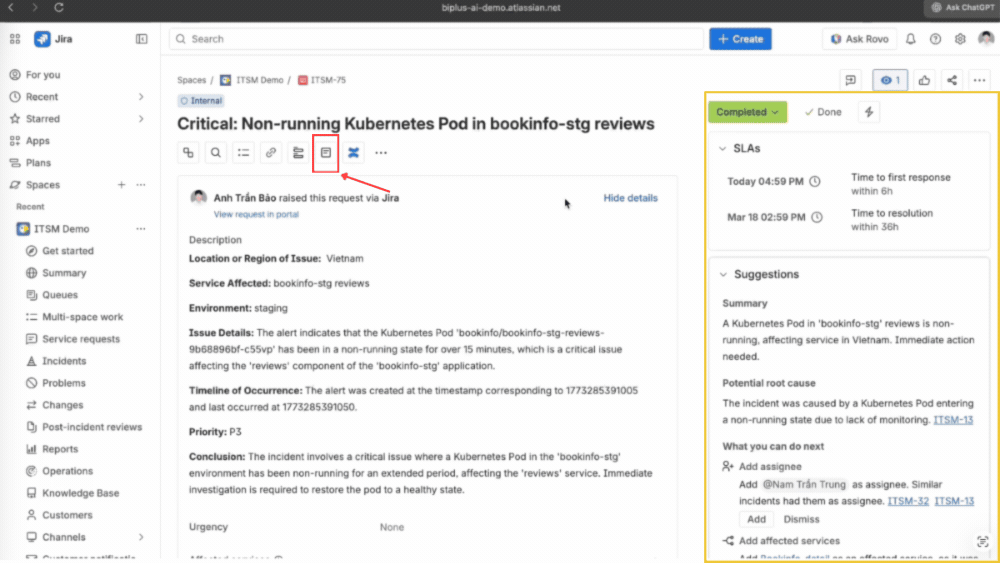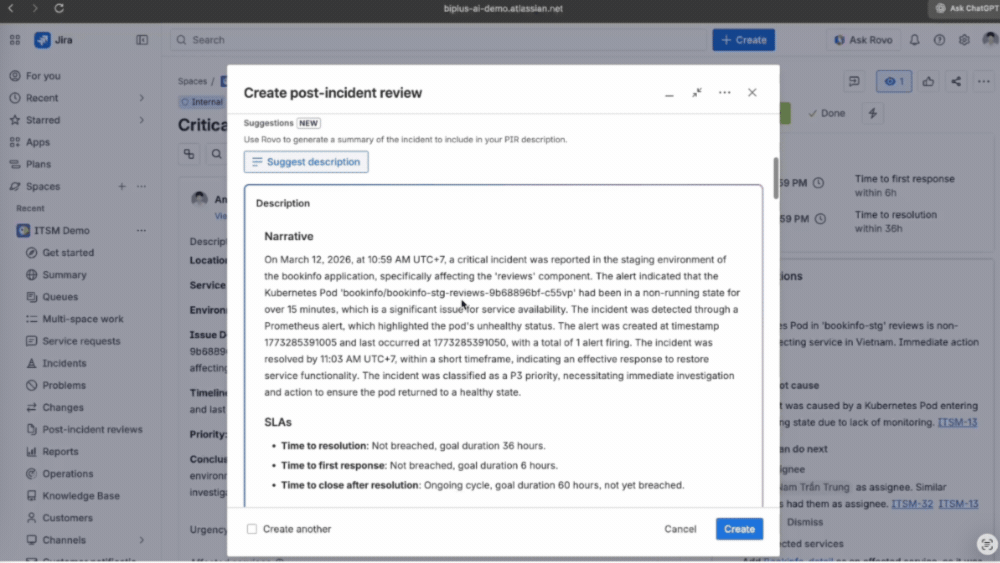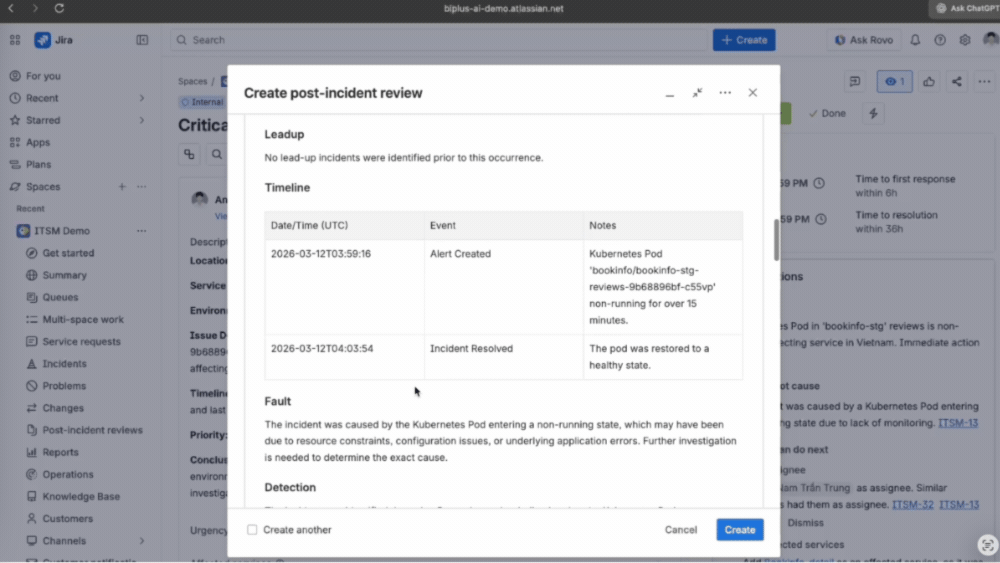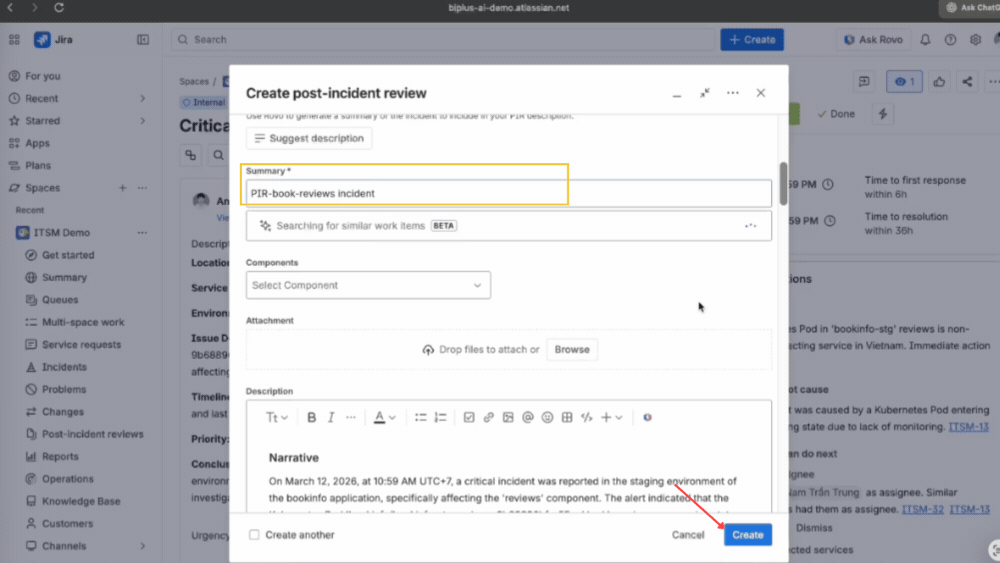
Thực hiện Post-Incident Review ngay trên hệ thống
Modern IT Operations không dừng lại ở việc xử lý xong một incident. Ngay sau khi sự cố được khắc phục, đội ngũ thực hiện Post-Incident Review trực tiếp trên hệ thống.
Rovo AI hỗ trợ tạo sẵn cấu trúc báo cáo, giúp ghi lại đầy đủ timeline, nguyên nhân gốc rễ và các hành động phòng ngừa. Toàn bộ nội dung sau đó được lưu vào knowledge base và liên kết lại với incident tương ứng.
Xây dựng hệ thống tri thức và vòng học hỏi liên tục
Theo thời gian, hệ thống tri thức này trở thành nền tảng giúp đội ngũ xử lý các sự cố tương tự nhanh hơn, đồng thời hạn chế việc lặp lại các lỗi cũ. Đây cũng là điểm khác biệt lớn nhất: mỗi incident không chỉ được xử lý, mà còn đóng góp vào việc cải thiện toàn bộ hệ thống vận hành.
Kết quả thực tế tại BiPlus
Sau khi áp dụng Modern IT Operations, sự thay đổi không chỉ nằm ở tốc độ mà còn ở cách đội ngũ vận hành. Thời gian phản hồi và xử lý sự cố được rút ngắn rõ rệt. Việc phối hợp giữa các team trở nên mượt hơn khi tất cả cùng làm việc trên một nguồn thông tin chung. Quan trọng hơn, đội DevOps không còn phụ thuộc vào từng cá nhân, mà đã xây dựng được một hệ thống vận hành có thể mở rộng và tái sử dụng.
Xem thêm cách BiPlus Tái thiết kế SDLC thành năng lực vận hành chiến lược với AI Agent
Kết luận
Modern IT Operations không chỉ là việc bổ sung thêm công cụ mới. Giá trị cốt lõi nằm ở việc kết nối dữ liệu, quy trình, con người và AI thành một hệ thống thống nhất. Khi làm được điều này, IT Ops không chỉ xử lý sự cố nhanh hơn mà còn trở thành nền tảng giúp doanh nghiệp vận hành ổn định và phát triển bền vững.
Nếu đội IT của bạn đang gặp những vấn đề tương tự, BiPlus có thể chia sẻ chi tiết hơn cách triển khai trong thực tế.
Tìm hiểu thêm về giải pháp Service Collection TẠI ĐÂY!







